大二下啃下 ROS2:我从零搞定 AGV 自主建图算法
从零学习 ROS2、实机部署踩坑、到提出结构感知驱动算法——记录我把一个自主建图研究从想法推到论文和发明专利的完整过程
项目概述#
| 项目属性 | 内容 |
|---|---|
| 项目名称 | 基于结构感知驱动的机器人室内自主探索建图方法 |
| 项目时间 | 2025.02 – 至今 |
| 项目类型 | ROS2 移动机器人算法科研 |
| 我的角色 | 论文第一作者、发明专利第一发明人 |
| 技术栈 | ROS2 (Humble)、Linux (Ubuntu)、C++、Python、Nav2、Gazebo、Docker |
| 成果 | 北核论文一作在投,发明专利一作受理(申请号:202610371925.X) |
为什么做这个项目#
大二上学期,我跟着唐文献老师进实验室不久。之前帮师兄写的超声波流量计 GP30 芯片驱动因为师兄毕业、实验台被拆,课题不了了之。唐老师和我聊了一次,说实验室有 AGV 设备,问我要不要试试做自主建图方向。
我当时对 ROS2 几乎一无所知。但”自主建图”这四个字让我很兴奋——让一台小车自己在陌生环境里探索、画地图,这不就是机器人最核心的能力之一吗?博士师兄郭胜给了我一个具体场景:在结构化室内环境中,让 AGV 自主完成建图,并且要跑得比现有方法更快、更稳。
那个学期我同时在打工程实践大赛和挑战杯,三门功课压在一起。但我给自己定了个规矩:每一个节点、每一个话题、每一个服务,都亲手敲,不复制粘贴。
当时 AI 写代码的能力已经很强了,周围也有同学直接用 AI 生成功能包。但我想得很清楚——我从初中开始搞信息学奥赛,见过太多”跑起来但不知道为啥跑起来”的例子。AI 生成的代码如果我不理解,出了问题就是黑箱。我要的是真懂,不是速成。
接下来两个月,我白天跑比赛,晚上回到宿舍就打开 B 站的 ROS2 教程,一行一行地敲。遇到不懂的通信机制,就去看官方文档,直到能在心里把节点之间的消息传递画出来。当我能独立写出第一个自主移动的功能包,让小车在仿真里成功跑起来的时候,我觉得那两个月的每一行代码、每一个深夜,都值了。
实机部署:一块旧板子和 Docker 曲线救国#
仿真跑通了,师兄给了我一台实车——一台装着一块 Firefly-RK3399 开发板的麦克纳姆轮 AGV。
这块板子有些年头了,官方系统只支持到 Ubuntu 20.04。而我要用的 ROS2 Humble,官方推荐系统是 Ubuntu 22.04。
当时我的想法很直接:那就给它刷一个 22.04。
于是,噩梦开始了。
我几乎试遍了能在社区找到的每一个 22.04 镜像。每一个都带着新问题:有的刷进去之后稳压芯片启动失败,整个板子开不了机;有的大小核调度异常,四个核心只认到两个;有的 GPU 加速完全无法启动;有的无线网卡驱动怎么都打不上。我前前后后折腾了将近两周,每一版镜像都是先满怀希望地烧录,再看着报错日志一点点凉下去。
最后还是放弃了。我装回了 Firefly 官方维护的那个 Ubuntu 20.04。但这一次,我没有认输——我突然意识到,可以在 20.04 上用 Docker 来跑 ROS2 Humble 的环境。
容器跑起来,ROS2 的节点一个个成功启动的那一刻,那两周在社区镜像里吞下的所有挫败,终于有了一个出口。
这段经历给我上了很重要的一课:工程上,不是所有问题都要正面硬刚。能找到绕过去的路,也是一种能力。 花了两周时间和一块旧板子较劲,才把它真正种进心里——我觉得不算亏。
核心方案:三个模块,一个完整算法#
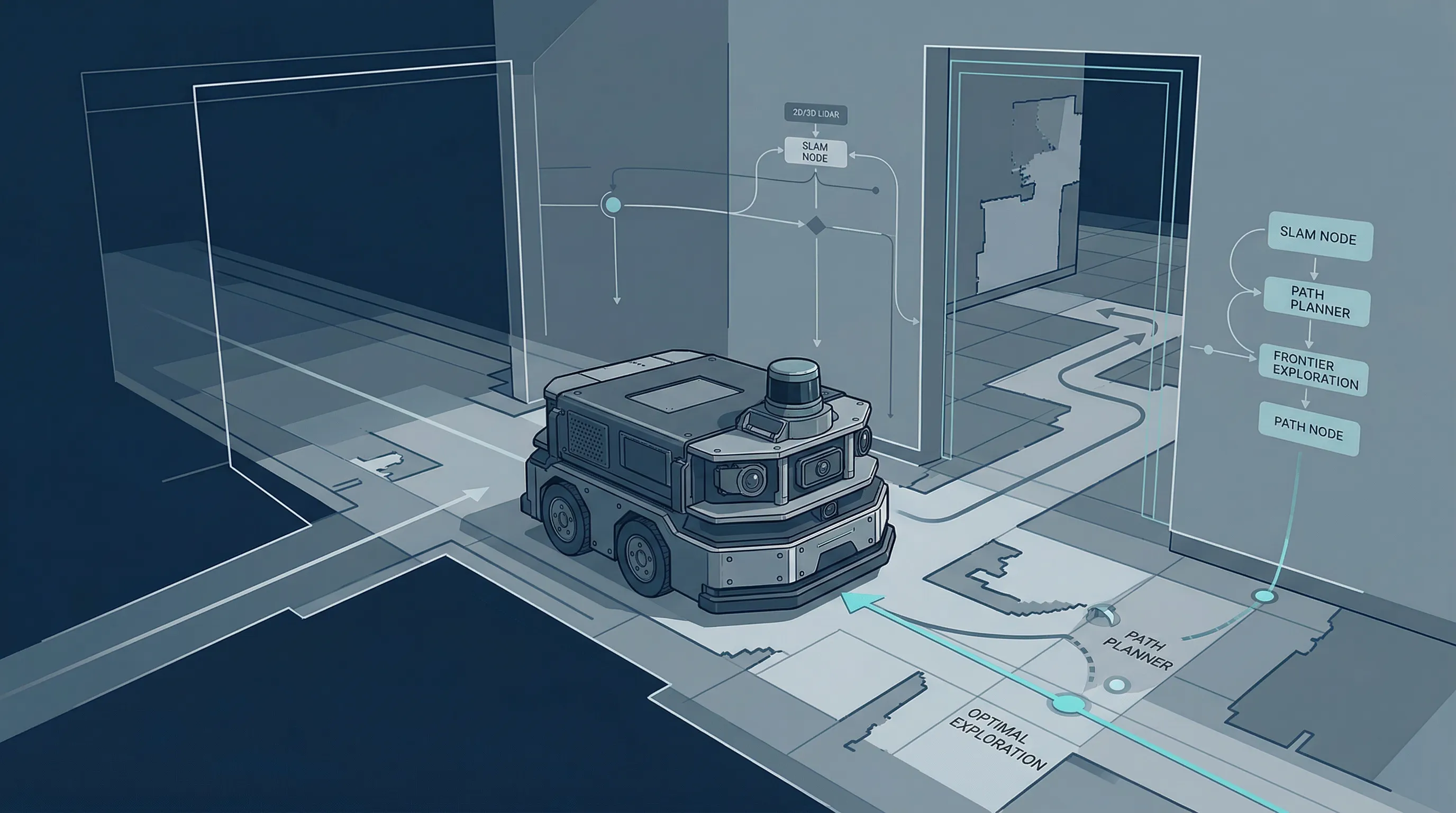
实机部署后,我可以手动操控小车进行 2D 激光建图了。当时常用的自主探索算法大多基于前沿点(Frontier)策略——找到未知区域和已知区域的边界,然后决策下一个目标点。但我在实际测试中发现一个现象:最后那 20% 的图,小车反反复复地在已建的区域打转,像在兜圈子。
我就想,人是怎么建图的?我们进入一个陌生的大楼,一定会先穿过门,找到走廊,把整个空间的骨架先摸清楚,然后再进到每个房间里面去看细节。人的脑子里有”门”和”走廊”这些结构概念——知道哪些地方是”咽喉要道”,值得优先通过。
那小车的算法里有这种概念吗?
我查了很多论文,发现当时大多数前沿点评估指标,都是信息增益、路程代价这些东西。几乎没有工作去显式地告诉机器人”这里是狭窄通道,这里是开阔区域,狭窄通道应该优先去”。
基于这个观察,我设计了一套融合三个模块的自主探索算法。
flowchart TB
subgraph 输入[感知输入]
GM[占据栅格地图]
UF[不确定性前沿 UF]
PF[前沿点候选集]
end
subgraph 模块一[模块一:结构感知项 S]
EDT[欧氏距离变换]
CW[通道宽度计算]
SF[分段评分函数]
EDT --> CW --> SF
end
subgraph 模块二[模块二:信息增益项 U]
RC[全向射线投射]
VA[可见性分析]
IG[累积信息收益]
RC --> VA --> IG
end
subgraph 模块三[模块三:导航代价项 R]
ED[欧氏距离近似粗筛]
PP[真实路径规划精筛]
ED -->|"Top-K 候选"| PP
end
输入 --> 模块一
输入 --> 模块二
输入 --> 模块三
模块一 --> MU[多目标效用融合
U = w1×S + w2×U + w3×R]
模块二 --> MU
模块三 --> MU
MU --> DA[动态权重调整]
DA --> TG[最优探索目标点]
模块一:结构感知项——让机器人”感受”通道的宽窄#
核心思路是:用纯几何方法,让机器人自己判断哪里是走廊、哪里是门洞、哪里是开阔空间。
具体做法:对当前的占据栅格地图做欧氏距离变换(Euclidean Distance Transform),计算地图上每个位置到最近障碍物的距离。在走廊和门洞这种狭窄通道的位置,候选点两侧的障碍物很近,距离变换值就小;在开阔区域,距离变换值就大。然后我设计了一个分段评分函数,把这个通道宽度映射成一个结构感知得分——在类似门洞的理想通道宽度区间 [1.5m, 2.5m] 内得分最高,在开阔区域得分退回到基线水平。
这样一来,不需要额外训练任何语义模型,仅靠几何信息,就能让算法对室内空间的骨架结构产生”感觉”。
当然,说”感觉”容易,真正落地到公式和代码上远没有那么简单。大二下的我,面对论文里那些矩阵运算和概率模型,确实很吃力。但那个时候我已经学会了把 AI 当成学习的助手——用它帮我拆解公式背后的物理含义,帮我理解地图熵为什么能衡量环境的不确定度。
模块二:Top-K 两阶段分层筛选#
结构感知解决了”往哪里去”的问题。但在实际测试中,我发现了另一个拦路虎:路径评估太慢了。
候选前沿点动辄几十上百个,如果对每一个都跑一次完整的全局路径规划——小车可能要原地等上好几分钟,这在实时探索里是不可接受的。总不能小车跑一步,停下来等四分钟做一次决策。
当时卡了很久。有一天我忽然想起计算机领域一个很经典的做法:Top-K。在很多搜索和推荐场景里,面对海量候选项,都是先做一次快速粗筛,保留 Top-K 个最优质的候选,然后再对这 K 个做精细计算。
我把这个思路搬了过来:
- 粗筛阶段:使用完整的多目标评价模型(结构感知 + 信息增益 + 导航代价),但导航代价项用欧氏距离近似代替真实的路径规划结果。这样既保持了多目标评估的综合性,又避免了高昂的规划计算。粗筛完成后,只保留得分最高的 K 个候选点。
- 精筛阶段:只对这 K 个候选点调用真实的全局路径规划器(Nav2 的 SmacPlanner),用实际规划出的路径长度和拥挤度,重新计算导航代价项,得到最终的综合效用排序。
计算复杂度从 O(N × P) 降到了 O(N + K × P)。K 取 10 的时候,不管总共有多少个候选点,需要跑真实路径规划的始终不超过 10 个。
效果立竿见影。小车不再需要在每次决策时等待上百次路径规划,决策延迟明显缩短。而且因为精筛阶段用的是真实的路径规划结果而非近似值,决策质量并没有因为粗筛的近似而明显下降。
这让我意识到:很多好的算法设计,不是发明了多么高深的新东西,而是把正确的已有策略放在正确的位置上。
模块三:动态权重调整——探索快结束了,就别再跑远路了#
仿真试验中我观察到一个挺有意思的现象:当探索进入收尾阶段、环境里剩下的未知区域已经很少的时候,如果还按原来的权重分配——信息增益占大头、导航代价占小头——机器人有时会为了追一个信息量其实没多大的遥远候选点,跑很长一段路。这在后期其实很不划算:跑了一分钟的路,得到的只是角落里巴掌大的一块未知区域。
我在评价模型里嵌入了一个动态权重调整机制,逻辑很简单:当前沿点数量降到阈值以下时,信息增益项的权重自动衰减,导航代价项的权重自动增强。
翻译成大白话就是:探索前中期,机器人积极地去覆盖新区域;到了收尾阶段,它变得”务实”了——优先清理自己身边的残余未知区域,而不是跑很远去贪最后一点信息量。
这个机制不复杂,但它反映了一个想法:一个好的探索算法,不应该只在某一种场景下好,而应该在探索的全生命周期里都保持稳定的决策质量。
实验数据:不只是”更好”,是”每次都更好”#
在 Gazebo 仿真环境中,使用 20m × 15m 的结构化室内场景(包含走廊、房间和门洞)进行测试。五次独立试验,对比三种方法:
| 性能指标 | SUR-Nav(本文) | 最近距离策略 | 提升幅度 |
|---|---|---|---|
| 探索完成时间 | 1674.7s | 2003.4s | -16.4% |
| 路径长度 | 193.1m | 225.2m | -14.3% |
| 决策延迟 | 169.5ms | 204.4ms | -17.1% |
| 覆盖效率 | 0.614m²/s | 0.523m²/s | +17.4% |
对比固定权重策略:
| 性能指标 | SUR-Nav(本文) | 固定权重策略 | 提升幅度 |
|---|---|---|---|
| 探索完成时间 | 1674.7s | 2280.5s | -26.6% |
| 路径长度 | 193.1m | 273.1m | -29.3% |
| 决策延迟 | 169.5ms | 362.4ms | -53.2% |
但我觉得最值得说的不是平均值的提升,而是稳定性。
五次独立试验,我的算法探索完成时间的标准差只有 ±20.3 秒,路径长度的标准差只有 ±3.8 米。对比之下,最近距离策略的时间标准差是 ±104.8 秒,固定权重策略是 ±150.4 秒——差了 5 到 7 倍。探索中后期的决策变异系数稳定在 5% 以内。
这意味着我的算法不是”偶尔好一次”,而是”每次都好”。对于一个要跑在真实硬件上的算法来说,这种稳定性可能比绝对性能的提升更重要。
实机验证在四轮麦克纳姆轮平台上完成,复现了优先通过门洞等关键连通位置的行为特征。
一个容易被忽略的巧思:信息增益项的工程化#
在算法设计中,信息增益这一项本身并不新鲜——很多前沿点探索方法都会用到。但我在实现层面做了一个可能被忽略但我觉得重要的工程化选择。
传统的信息增益计算通常是在候选点位置模拟放置一个激光传感器,统计能观测到多少未知栅格。这个方法的缺陷是:如果候选点前方有一个障碍物遮挡,实际能看到的未知区域远少于理论值,但传统方法会高估信息增益。
我的做法是:构建一个”不确定性前沿”(Uncertainty Frontier, UF)——同时满足高熵与高梯度的边界栅格集合。然后不是从单个候选点去评估,而是对这个集合中的每一个 UF 栅格,从候选点出发做全向射线投射可见性分析,累积那些真正”可见”的未知栅格的预期信息收益。
这个改动不大,但它把”我能看到多少信息”变成了”我能看到多少环境真正不确定的地方”,让信息增益项的评估更加精准。这也是为什么在探索中后期,当剩余未知区域分散且边界不规则时,我的算法仍然能保持较低决策变异系数的原因之一。
复盘:做对了什么,做错了什么#
做对了的:
- 手敲代码的决策。那两个月的慢功夫,让我对整个 ROS2 框架有了肌肉记忆。后来实机部署出问题时,我能快速定位到是节点通信的问题还是硬件驱动的问题,靠的就是那段时间打下的底子。
- 从观察到问题定义。不是看到论文里说”某某方法有问题”就跟着做,而是自己跑仿真、看小车在里面是怎么打转的,然后想”人是怎么做的”。这种从第一性原理出发的思考方式,让我最终提出的方案跟我看到的真实问题是对得上的。
- Docker 曲线救国。在板子上死磕两周之后选择放弃强攻、换一个思路,这个决策当时做得很痛苦,但现在回头看是正确的。工程上,找到代价最小的通路比证明”我能硬扛”更重要。
做错了的:
- 前期调研不够系统。我一上来就跟着教程学 ROS2 操作,但对 SLAM 和自主探索领域的文献调研是后来才补的。如果能早点了解这个方向的研究现状,也许可以少走一些弯路,尤其是在信息增益项的实现上。
- 没有尽早做参数灵敏度分析。K 值的选取、权重衰减的阈值,都是在仿真跑了很多轮之后才系统地去调的。如果一开始就设计好灵敏度分析的实验方案,可以省不少时间。
- 结构感知项在弱几何特征场景下的退化处理不够优雅。在空旷厂房这种场景下,通道宽窄的概念本身就变得模糊,我的分段评分函数虽然在开阔区域退化到基线,但退化曲线是硬切的,不够平滑。这是后续研究需要改进的地方。
可迁移收获#
这个项目教会我的,不只是 ROS2 怎么用、算法怎么写。
第一,完整的科研闭环能力。 从文献调研 → 问题定义 → 算法设计 → 仿真建模 → 实机部署 → 对比实验 → 数据分析 → 论文和专利撰写,我一个人走了一遍。这意味着将来进组后,我可以直接上手,不需要从头培养。
第二,在多个”好选择”之间做取舍的能力。 算法设计里到处都是 trade-off:精度和实时性、探索和利用、开阔区域和狭窄通道。学会识别这些 trade-off 并在给定约束下做出有依据的取舍,是我觉得从科研训练中收获的最通用的能力。
第三,不再和墙死磕。 那块 Firefly 板子教会我的事。真正的工程思维不是硬扛,而是找到代价最小的通路。
相关资源#
- 发明专利:已受理,申请号 202610371925.X(第一发明人)
- 学术论文:北核在投(第一作者)
初稿写于 2025 年 12 月,2026 年 4 月根据项目复盘更新。